3.1.3 결정 트리
결정트리란?
데이터를 이진 분류(0 또는 1)하거나 결괏값을 예측하는 분석 방법 //결과 모델이 트리 구조여서 결정 트리라고 함
결정트리를 사용하는 이유와 적용환경
- 사용하는 이유 : 주어진 데이터 분류
- 적용 환경 : 이상치가 많은 값으로 구성된 데이터셋을 다룰때 사용하기 좋음. 머신 러닝이 어떤 방식으로 의사결정하는지 알고싶을때 유용
(결정 과정이 시각적으로 표현되기 때문)
결정 트리 프로세스 + 사례

데이터를 1차 분류
→ 각 영역의 순도는 증가, 불순도와 불확실성은 감소하는 방향으로 학습 진행
+ 순도와 불순도
순도=균질성 : 범주 안에서 같은 종류의 데이터만 보여 있는 상태
불순도 : 서로 다른 데이터가 섞여있는 상태

((불확실성 = 데이터 분류에 있어서 a인지 b인지 불확실한 판단을 의미?))
✔ 정보 획득(Information gain) : 순도 증가, 불확실성 감소하는 것
결정트리에서 불확실성 계산
방법1. 엔트로피(Entropy)
확률 변수의 불확실성을 수치로 나타낸 것
엔트로피↑ = 불확실성↑
예) 엔트로피 값이 0, 0.5일때
엔토로피 = 0 = 불확실성 최소 = 순도 최대
엔토로피 = 0.5 = 불확실성 최대 = 순도 최소 //불확실성과 순도는 역의 관계
레코드 m개가 A 영역에 포함되어 있을 때 엔트로피 정의
//레코드(=인스턴스) : 분류 작업의 입력 데이터

예) 동전을 두 번 던져 앞면이 나올 확률이 1/4, 뒷면이 나올 확률이 3/4일때 엔트로피
- 레코드(입력데이터) : 2
- Pk : 1/4, 3/4
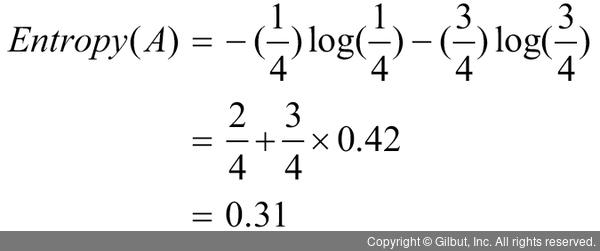
방법 2. 지니 계수(Gini index)
불순도를 측정하는 지표. 즉 원소 n개 중에서 임의로 두 개를 추출했을 때 추출된 두 개가 서로 다른 그룹에 속해 있을 확률
(데이터의 통계적 분산 정도를 정량화해서 표현한 값)
지니계수 공식

* 로그를 계산할 필요X → 엔트로피보다 계산이 빨라 결정트리에서 많이 사용
예제 - 타이타닉 승객의 생존 여부 예측

혼동 행렬
알고리즘 성능평가에 이용
| 실제 값 | 예측 값 | |
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
True Positive : 모델이 1이라고 예측 & 실제값도 1인 경우
True Negative : 모델이 0이라고 예측 & 실제값도 0인 경우
False Positive : 모델이 1이라고 예측 but 실제값은 0인 경우
False Negative : 모델이 0이라고 예측 but 실제값은 1인 경우 //true · false(앞) : 실제 값 //positive · negative(뒤) : 예측값
혼동 행렬 훈련 결과

해석 : 잘못된 예측보다 정확한 예측(네모칸)의 수치가 더 높으므로 잘 훈련됨
➕ 랜덤 포레스트 : 결정 트리를 좀 더 확대한 것(결정 트리를 여러 개 묶어놓은 것)
'Etc > Deep Learning' 카테고리의 다른 글
| 머신러닝 핵심 알고리즘(3) - 지도학습(로지스틱 회귀와 선형 회귀) (0) | 2021.07.21 |
|---|---|
| 3장(2) 실습 - 결정트리(타이타닉 승객 생존 여부 예측) | 대괄호 인덱싱 | map() | dropna(), drop() | DecisionTreeClassifier() | Confusion Matrix (0) | 2021.07.20 |
| 3장(1) 실습 - Pandas 기초 | Tensorflow 기초 | KNN, SVM 구현 예제 설명 (0) | 2021.07.19 |
| 3장 머신러닝 핵심 알고리즘(1) - 지도학습(K-최근접 이웃, 서포트 벡터 머신) (0) | 2021.07.19 |
| 2장 텐서플로 기초 (0) | 2021.07.14 |