3.1 지도학습
레이블을 컴퓨터에 미리 알려주고 데이터를 학습시키는 방법
지도학습 종류
1. 분류 : 주어진 데이터를 정해진 범주에 따라 분류
2. 회귀 : 데이터들의 특성을 기준으로 연속된 값을 그래프로 표현하여, 패턴이나 트렌드를 예측할 때 사용
+ 분류와 회귀의 차이
| 구분 | 분류 | 회귀 |
| 데이터 유형 | 이산형 데이터 | 연속형 데이터 |
| 데이터 예 | 성별, 종교, 지역 | 점수, 몸무게, 키 |
| 결과 | 훈련 데이터의 레이블 중 하나를 예측 | 연속된 값을 예측 |
| 예시 | 학습 데이터를 A/B/C 그룹 중 하나로 매핑 예) 스팸 메일 필터링 |
결괏값이 어떤 값이든 나올 수 있음 예) 주가 분석 예측 |

3.1.1 K-최근접 이웃
K-최근접 이웃이란?
새로운 입력(분류되지 않은 검증 데이터)을 받았을 때 기존 클러스터의 모든 데이터와 인스턴스 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘 //인스턴스 : 새로운 입력을 받았을 때 데이터와 데이터 사이의 거리를 측정한 관측치(데이터 값)
- 과거 데이터를 사용하여 미리 분류 모형을 만듦 (X)
- 과거 데이터를 저장해 두고 필요할 때마다 비교 (O) → K값의 선택에 따라 새로운 데이터에 대한 분류결과가 달라질 수 있음
K-최근접 이웃을 사용하는 이유와 적용환경
- 사용하는 이유 : 주어진 데이터를 분류하기 위해
- 적용 환경(사용 시점) : 훈련 데이터를 충분히 확보할 수 있는 환경, 초보자(직관적, 사용하기 쉬움)
분류 과정
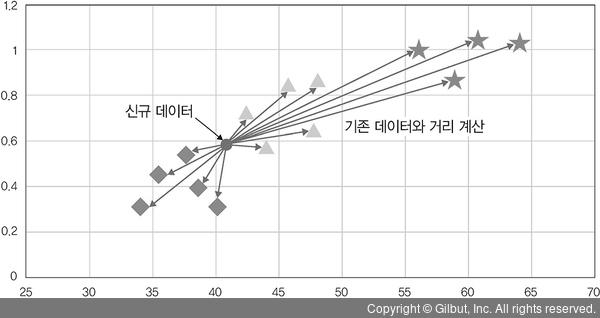
신규 데이터인 동그라미 유입
→ 기존 데이터들과 하나씩 거리를 계산
→ 거리상으로 가장 가까운 데이터 다섯 개(K=5)를 선택
→ 해당 클러스터에 할당
예제1 - K=3 일때, 새로운 입력에 대한 분류
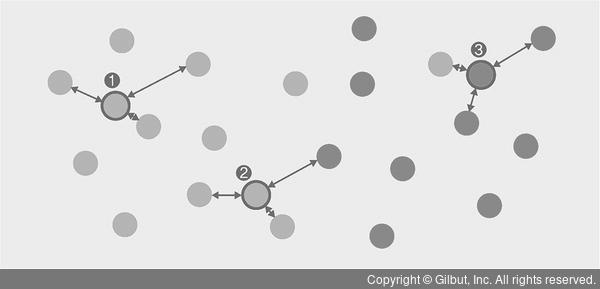
① 주변 범주 3개가 주황색 → 주황색으로 분류
② 주변 범주 2개가 주황, 1개가 녹색 → 주황색으로 분류
③ 주변 범주 2개가 녹색, 1개가 주황 → 녹색으로 분류
예제2 - 붓꽃 분류
//머신 러닝 코드는 심층 신경망이 필요하지 않기 때문에 사이킷런을 이용
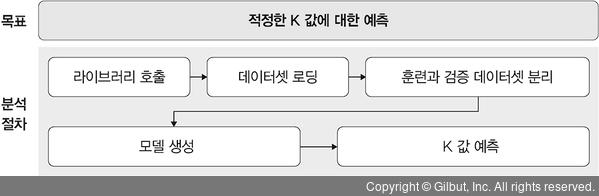
K값 예측 과정
3.1.2 서포트 벡터 머신
서포트 벡터 머신이란?
분류를 위한 기준선을 정의하는 모델
즉, 분류되지 않은 새로운 데이터가 나타나면 결정 경계(기준선)을 기준으로 경계의 어느쪽에 속하는지 분류함
서포트 벡터 머신을 사용하는 이유와 적용 환경
- 사용하는 이유 : 주어진 데이터에 대한 분류
- 적용 환경 : 정확도를 요구하는 분류 문제, 텍스트 분류
서포트 벡터 머신 관련 개념
1. 결정 경계
데이터를 분류하기 위한 기준선
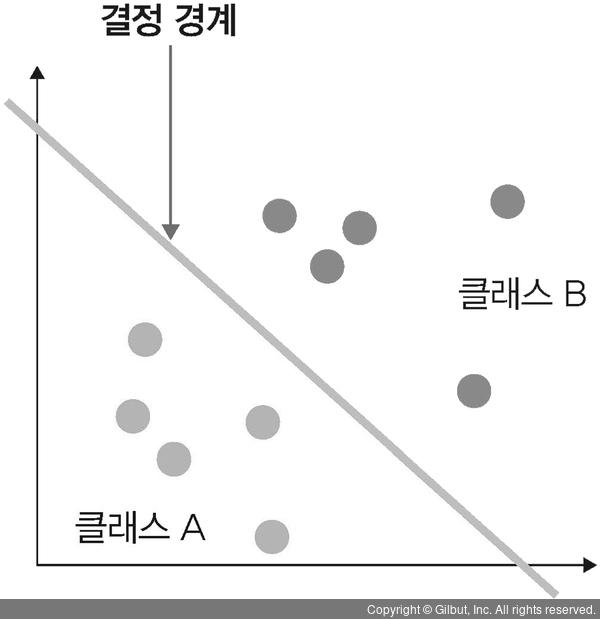
서포트 벡터 머신 결정 경계의 위치 결정
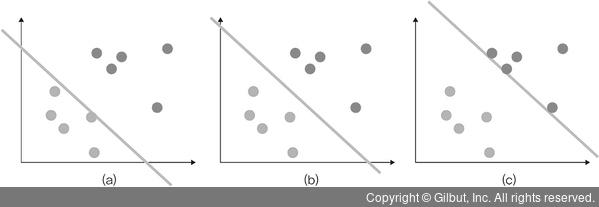
결정 경계는 데이터가 분류된 클래스에서 최대한 멀리 떨어져있을 때 성능이 가장 좋음(위 그림에선 (b)가 베스트)
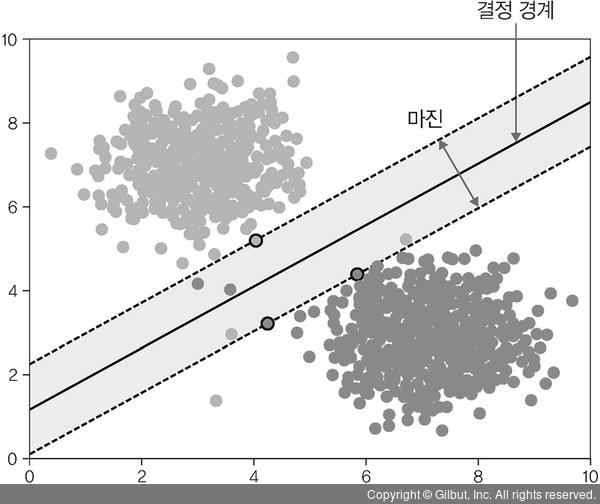
2. 마진
결정 경계와 서포트 벡터 사이의 거리
//서포트 벡터란? 결정 경계와 가까이 있는 데이터들(이 데이터들이 경계를 정의하는 결정적인 역할을 함)

∴ 최적의 결정 경계
: 마진크기를 최대로 해야함
//결정 경계는 클래스에서 최대한 멀리 떨어져있을때 성능이 가장 좋음
결국 이상치(패턴에서 벗어난 값)을 잘 다루는 것이 중요
+ 이상치에 따른 분류
- 하드 마진 : 이상치를 허용X 예)그림 3-7
- 소프트 마진 : 어느 정도의 이상치들이 마진 안에 포함되는 것을 허용O 예)그림 3-8
예제 - 붓꽃 분류

(목표가 K-최근접 이웃과 다름 - 적정한 K값에 대한 예측)
svm = svm.SVC(kernel='linear', C=1.0, gamma=0.5)
① 커널
커널 : 결정 경계 긋기
SVM은 '선형 분류'와 '비선형 분류'를 지원 //비선형에 대한 커널은 선형으로 분류될 수 없는 데이터들 때문에 발생
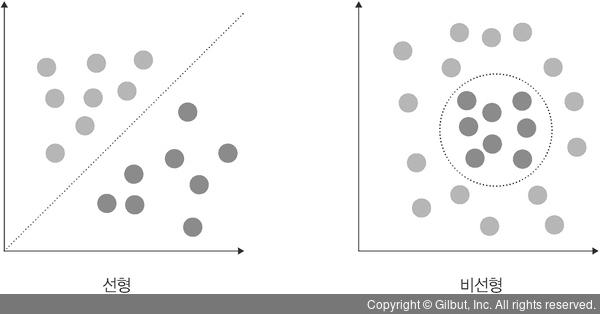
비선형 문제를 해결하는 가장 기본적인 방법 : 저차원 데이터를 고차원으로 보내는 것
//저차원 데이터 : 특성이 적은 데이터 | 고차원 데이터 : 특성이 많은 데이터
- 문제 : 많은 수학적 계산이 필요하므로 성능에 문제를 줄 수 있음
+ 커널 트릭
위 문제를 해결하고자 도입(선형으로 분리할 수 없는 점들을 분류하기 위해 사용)
커널 분류
| 선형 모델을 위한 커널 | - 선형 커널 |
| 비선형 모델을 위한 커널 | - 가우시간 RBF 커널 - 다항식 커널 |
- 선형 커널

- 선형적으로 분류 가능한 데이터에 적용, 기본 커널 트릭(즉 커널 트릭을 사용하지 않겠다는 의미)
- 다항식 커널

- 실제로는 특성 추가X, 그러나 다항식 특성을 많이 추가한 것과 같은 결과를 얻을 수 있는 방법(다항식 특성을 많이 추가한 것과 같은 결과 == 엄청난 수의 특성 조합이 생기는 것과 같은 효과를 얻음 → 고차원으로 데이터 매핑이 가능하게 함)
- 가우시안 RBF 커널

- 다항식 커널의 확장. 입력 벡터를 차원이 무한한 고차원으로 매핑하는 것으로, 모든 차수의 모든 다항식을 고려(차수에 제한 없이 무한한 확장이 가능) //다항식 커널은 차수에 한계O
② C
오류를 어느 정도 허용할지 지정하는 파라미터
- C값이 클 수록 하드마진, 작을 수록 소프트 마진
③ 감마
결정 경계를 얼마나 유연하게 그을건지 지정(훈련 데이터에 얼마나 민감하게 반응할지)
※감마 값이 높으면 훈련 데이터에 많이 의존 → 결정 경계가 곡선 형태(구불구불)를 띠며 과적합을 초래할 수 있으므로 주의
감마 값이 낮으면 학습 데이터에 별로 의존하지 않고 결정 경계를 직선에 가깝게 그음(언더피팅 발생 가능성 有)

커널, 감마 참고 블로그 : http://hleecaster.com/ml-svm-concept/
'Etc > Deep Learning' 카테고리의 다른 글
| 3장(2) 실습 - 결정트리(타이타닉 승객 생존 여부 예측) | 대괄호 인덱싱 | map() | dropna(), drop() | DecisionTreeClassifier() | Confusion Matrix (0) | 2021.07.20 |
|---|---|
| 3장 머신러닝 핵심 알고리즘(2) - 지도학습(결정 트리) (0) | 2021.07.20 |
| 3장(1) 실습 - Pandas 기초 | Tensorflow 기초 | KNN, SVM 구현 예제 설명 (0) | 2021.07.19 |
| 2장 텐서플로 기초 (0) | 2021.07.14 |
| 1장 머신러닝과 딥러닝 (0) | 2021.07.12 |