2.1 텐서플로 개요
'데이터 흐름 그래프'를 사용하여 '데이터의 수치 연산'을 하는 오픈소스 소프트웨어 프레임워크
데이터 흐름 그래프

벡터, 행렬, 텐서의 형태
✔벡터: 인공지능에서의 데이터, 1차원 배열 형태
✔텐서: 3차원 이상의 배열 형태

2.1.1 텐서플로 특징 및 장점
- GradientTape로 자동으로 미분을 계산할 수 있음(역전파 계산 과정 - 가중치값 업데이트(오차 최소화를 위해)에 사용)
+ 분산 환경에서 실행가능 //분산환경 : 데이터를 조작, 함수를 수행시 원격지의 것들을 사용할 수 있음
2.1.2 텐서플로의 일반적인 아키텍처

1. 모델(모형) 생성 : 데이터 훈련을 위한 '데이터셋과 모델' 생성, 훈련할 수 있는 환경 제공. 텐서보드 등의 도구 제공
//텐서보드 ; 모델의 학습 과정을 시각화하여 보여줄 수 있음
2. 모델(모형) 저장 : 텐서플로는 분산 환경에서 모델 '저장, 배포'할 수 있는 환경 제공
+ 웹, 모바일 모두 사용가능하도록 호환성이 고려된 모델 저장소를 제공
3. 모델(모형) 배포 : 서버/웹 환경에서 텐서플로 사용하면 언어/플랫폼에 상관없이 모델을 쉽게 학습, 배포할 수 있음
2.2 텐서플로 2.x 기초 문법
딥러닝 API '케라스'로 딥러닝 모델 구현 가능
2.2.1 데이터 준비
데이터 호출방법 : ① 판다스 ② 텐서플로
데이터 처리방법
① 데이터가 이미지인 경우(이미지 모델을 사용해야 하는 경우)
분산된 파일에서 데이터를 읽음 → 전처리 → 배치(batch)단위로 분할하여 처리
② 데이터가 텍스트인 경우(텍스트 모델을 사용해야 하는 경우)
임베딩 → 서로 다른 길이의 시퀀스를 배치단위로 분할하여 처리
//임베딩: 자연어를 기계가 이해할 수 있는 숫자 형태인 벡터로 바꾼 결과 및 그 과정
텐서플로를 이용하여 데이터셋을 불러오는 방법(예시 코드: 39p)
① 임의 데이터셋 사용 : 임의의 데이터들을 Dataset으로 만든 후 텐서(tf.Tensor)로 변환하여 사용
② 텐서플로에서 제공하는 데이터셋 사용 : 이때 tensorflow_datasets라는 별도의 패키지 이용
③ 케라스에서 제공하는 데이터셋 사용 : 이때 텐서플로에서 제공하는 케라스 모듈 사용
④ 인터넷에서 데이터셋을 로컬 컴퓨터에 내려받아 사용 : 이때 텐서플로에서 제공하는 tf.keras.utils.get_file 메서드 사용
2.2.2 모델 정의
모델 정의 방법
① Sequential API를 이용
:케라스를 이용한 API

- 최상위에 '케라스'가 있음
케라스는 '텐서플로 런타임'을 이용하여 동작함
- 텐서플로는 CPU와 GPU 환경에서 실행 가능
✔한계 : 단순히 층을 여러개 쌓는 형태이므로 복잡한 모델 생성은 어려움
✔ 텐서플로2에서 케라스 사용하기
from tensorflow.keras import models, Dense //(1)텐서플로 안에 있는 케라스 라이브러리를 가져와서
model = tf.keras.sequential() //(2)케라스 라이브러리 안에 있는 models 모듈에서 sequential()을 가져옴
② Functional API를 이용
:Sequential API로 복잡한 모델을 생성할 때의 한계를 극복할 수 있음
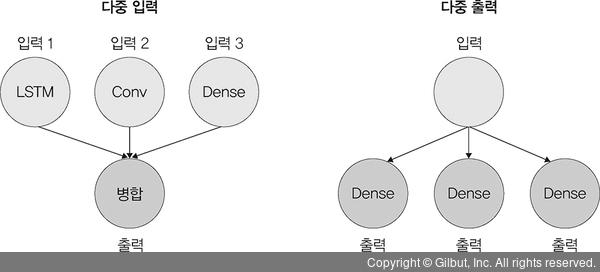
- '다중 입력, 다중 출력' 등 복잡한 모델 정의 가능
('입력과 출력을 사용자가 정의'해서 모델 전체를 규정할 수 있기 때문)
✔ Functional API와 Sequential API의 차이
- Functional API는 입력 데이터의 크기(shape)를 input()의 파라미터로 사용하여 입력층을 정의해줘야 함 //3줄
- 이전 층을 다음 층의 입력으로 사용 //예시코드의 x, 5줄
- model()에 입력과 출력을 정의 //마지막 줄
✔Functional API를 이용한 예시 코드
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
inputs = Input(shape=( 5, ) ) ------ 입력층(열(특성) 다섯 개를 입력으로 받음)
x = Dense( 8, activation="relu" )( inputs ) ------ 은닉층 1
x = Dense( 4, activation="relu" )( x ) ------ 은닉층 2
x = Dense( 1, activation="softmax" )( x ) ------ 출력층
model = Model(inputs, x)
③ Model Subclassing API 이용
:본질적으론 Functional API와 큰 차이가 없으나, 사용자가 가장 자유롭게 모델을 구축할 수 있는 방법
모델을 정의하는 방법 선택 후 계층 만들기
계층 : x를 입력으로 받아 y를 출력하는 형태의 계산을 표현
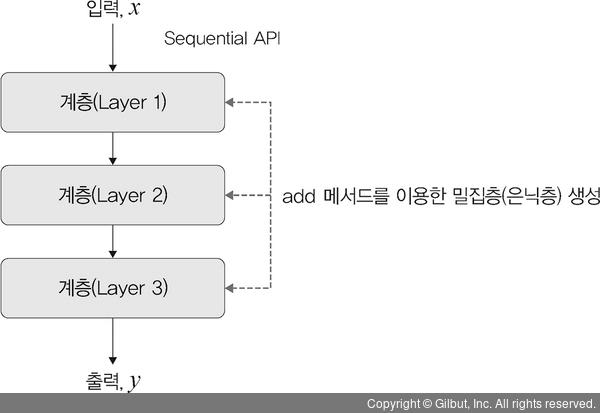
- 밀집층 : 입력과 출력을 연결
└ 입력과 출력을 연결하는 가중치를 포함하고 있음
└ 'add 메서드'를 사용하여 모형에 계층을 추가
model.add(Dense(4, activation='sigmoid',
input_shape=(4, ), weights=(w, b), name="dense1"))
2.2.3 모델 컴파일
모델을 훈련하기 전에 필요한 파라미터들을 정의
사전에 정의할 파라미터
① 옵티마이저 : 데이터와 손실함수를 바탕으로 모델의 업데이트 방법을 결정
② 손실함수 : 훈련하는 동안 출력과 실제값(정답) 사이의 오차를 측정
즉 wx+b를 계산한 값과 실제 y의 오차를 구해서 모델 정확성을 측정
③ 지표 : 훈련과 검증단계를 모니터링하여 모델의 성능을 측정
✔ 컴파일 예시 코드
model.compile(optimizer='adam', //아담 옵티마이저 사용
loss='sparse_categorical_crossentropy', //다중 분류에서 사용되는 손실함수
metrics=['accuracy']) //훈련에 대한 정확도를 나타냄, 값이 1에 가까울수록 좋은 모델
2.2.4 모델 훈련
앞에서 만든 데이터로 모형을 학습시킴
학습을 시킨다 : y=wx+b라는 매핑 함수에서 w와 b의 적절한 값을 찾는 것 //x는 input, y는 output
✔모델 훈련 예시 코드

ⓐ 입력 데이터 ⓑ 결과(label) 데이터
ⓒ 학습 데이터 반복 횟수 ⓓ 한 번에 학습할 때 사용하는 데이터 개수
ⓔ 검증 데이터 (각 에포크마다 검증 데이터의 정확도도 함께 출력됨. 모델이 검증 데이터를 학습하진 않음)
ⓕ 학습 진행 상황을 보여줄지 지정 (1값으로 설정하면 학습 진행 상황을 볼 수 있음)
2.2.5 모델 평가
주어진 검증 데이터셋을 사용하여 모델을 평가함
평가가 끝나면 검증 데이터셋에 대한 손실값과 정확도가 결과로 표시됨
✔ 모델 평가 예시 코드

ⓐ 검증 데이터셋
ⓑ 결과(label) 데이터셋
ⓒ 한 번에 학습할 때 사용하는 데이터 개수
2.2.6 훈련 과정 모니터링
텐서보드를 이용하면 학습에 사용되는 각종 파라미터 값이 어떻게 변화하는지 시각화하여 볼 수 있음
✔ 텐서보드 사용
log_dir = "logs/fit/"
// ①콜백함수를 만들고 log_dir변수를 넣음
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
// ②model.fit()메서드의 마지막 파라미터로 callbacks에 tensorboard_callback를 넣음
model.fit( x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]) ------ model.fit() 안에 callbacks를 옵션으로 넣어 줍니다.
//③cmd(주피터 노트북)에서 텐서보드 실행
tensorboard --logdir=./logs/fit/
//④웹브라우저에서 localhost:6006입력
① tensorboard_callback의 파라미터

ⓐ 로그가 저장될 디렉터리 위치 지정
ⓑ histogram_freq: histogram_freq=1 : 모든 에포크마다 히스토그램 계산(값에 대한 분포도 확인 용도)을 활성화
기본값은 0으로 비활성화되어 있음
2.2.7 모델 사용
훈련된 모델을 사용해 실제 예측을 진행
model.predict(y_test)
'Etc > Deep Learning' 카테고리의 다른 글
| 3장(2) 실습 - 결정트리(타이타닉 승객 생존 여부 예측) | 대괄호 인덱싱 | map() | dropna(), drop() | DecisionTreeClassifier() | Confusion Matrix (0) | 2021.07.20 |
|---|---|
| 3장 머신러닝 핵심 알고리즘(2) - 지도학습(결정 트리) (0) | 2021.07.20 |
| 3장(1) 실습 - Pandas 기초 | Tensorflow 기초 | KNN, SVM 구현 예제 설명 (0) | 2021.07.19 |
| 3장 머신러닝 핵심 알고리즘(1) - 지도학습(K-최근접 이웃, 서포트 벡터 머신) (0) | 2021.07.19 |
| 1장 머신러닝과 딥러닝 (0) | 2021.07.12 |