6.2 객체 인식을 위한 신경망
객체 인식이란?
이미지나 영상 내에 있는 객체를 식별하는 컴퓨터 비전 기술
→ 이미지 · 영상 내에 있는 객체가 무엇인지 분류 & 그 객체의 위치가 어디인지 박스로 나타내는 위치 검출
딥러닝을 이용한 객체 인식 알고리즘
: 1단계 객체 인식, 2단계 객체 인식으로 나눌 수 있음
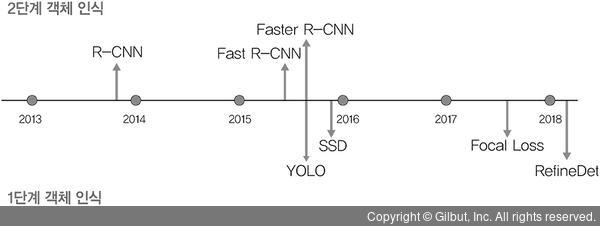
<1단계 객체 인식 vs 2단계 객체 인식 흐름도>
1단계 객체 인식 : 분류와 위치 검출 문제를 동시에 행하는 방법(빠르고 낮은 정확도) - YOLO, SSD 계열
2단계 객체 인식 : 두 문제를 순차적으로 행하는 방법(느리고 높은 정확도) - R-CNN 계열
6.2.1 R-CNN
예전의 객체 인식 알고리즘
- 슬라이딩 윈도우 방식
: 이미지의 객체를 탐색하고자 이미지 왼쪽 상단부터 일정 크기의 경계 상자(윈도우)를 만들고 그 안에서 객체를 탐색하는 과정을 반복하여 객체를 검출해 내는 방식
- 단점 : 알고리즘의 비효율성
⇒ 현재 : 선택적 탐색 알고리즘을 적용한 후보 영역을 많이 사용
//선택적 탐색 알고리즘 : 하단 Note 참고 //후보 영역 : 영상 · 이미지에서 객체가 있을 법한 영역
R-CNN이란?
이미지 분류를 수행하는 CNN + 이미지에서 객체가 있을만한 영역을 제안해주는 후보영역 알고리즘 결합
R-CNN의 수행과정

① 이미지를 입력으로 받음
② 2000개의 바운딩 박스를 선택적 알고리즘으로 추출한 후 crop하고, 같은 크기로 통일함(CNN 모델에 넣기 위헤)
③ 크기가 동일한 이미지 2,000개에 각각 CNN 모델을 적용
④ 각각 분류를 진행하여 결과를 도출함
📝Note. 선택적 탐색
선택적 탐색이란?
- 객체 인식이나 검출을 위한, 가능한 후보 영역을 알아내는 방법
- 시드 선정(분할 방식 이용) → 그 시드에 대한 완전 탐색 적용
선택적 탐색의 과정
1단계. 초기 영역 생성 : 입력된 이미지를 영역 다수개로 분할
2단계. 작은 영역의 통합 : 1단계에서 나눈 영역들을 비슷한 영역으로 통합함(greedy 알고리즘 사용. 비슷한 영역이 하나로 통합될 때까지 반복)
3단계. 후보 영역 생성 : 통합된 영역을 기반으로 후보 영역(바운딩 박스)를 추출함
용어
• 완전 탐색: 후보가 될 만한 대상의 다른 상황(크기 · 비율)을 고려해서, 후보 영역을 찾는 기법
• 분할: 영상 데이터의 특성(색상, 모양, 무늬 등)에 따라 분할하여 후보 영역을 선정하는 기법
• 후보 영역(바운딩 박스): 3D 객체의 형태를 모두 포함할 수 있는 최소 크기의 박스
• 시드: 영상에서는 특정 기준점의 픽셀에서 점점 의미가 같은 영상 범위까지 픽셀을 확장해 나가면서 분할함. 이때 특정 기준점이 되는 픽셀
• 그리디 알고리즘 : 여러 가지 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식



❗ R-CNN의 단점
1. 세 단계의 복잡한 학습 과정
2. 긴 학습시간과 대용량 저장 공간
3. 객체 검출 속도 문제
⇒ 해결 : Fast R-CNN
6.2.2 공간 피라미드 풀링
기존 CNN 구조
완전연결층을 위해 입력 이미지를 고정해야함
→ 신경망을 통과시키려면 고정된 크기로 자르거나 비율을 조정
→ ❗ 문제 : 물체의 일부분이 잘림 · 본래의 생김새와 달라짐
⇒ 해결 : 공간 피라미드 풀링


공간 피라미드 풀링이란?
'입력 이미지의 크기에 상관없이 합성곱층을 통과'시킴 & 완전연결층에 전달되기 전에 특성 맵들을 동일한 크기로 조절해주는 풀링층을 적용
→ 장점
- 이미지의 특징이 훼손되지 않은 특성 맵을 얻을 수 있음(입력 이미지의 크기 조절 없이 합성곱층을 통과시키므로)
- 이미지 분류, 객체 인식같은 여러 작업에 적용할 수 있음
6.2.3 Fast R-CNN
R-CNN의 문제 : 바운딩 박스마다 CNN을 돌림, 분류를 위한 긴 학습시간
Fast R-CNN(Fast Region-based CNN) : R-CNN의 속도 문제 개선을 위해 Rol 풀링 도입
- 선택적 탐색에서 찾은 바운딩 박스 정보가 CNN을 통과하면서 유지되도록 함
- 최종 CNN 특성맵은 풀링을 적용하여 완전연결층을 통과하도록 크기를 조정

📝Note. Rol 풀링
Rol 풀링이란?
크기가 다른 특성맵의 영역마다 스트라이드를 다르게 최대 풀링을 적용 → '결과값 크기를 동일하게' 맞추는 방법
예) 박스 한 개가 픽셀 한 개를 뜻하는 특성맵
8×8 특성 맵(➊)에서 선택적 탐색으로 뽑아낸 7×5 후보 영역(➋)이 있음
이 영역(➋)을 2×2로 만들기 위해 스트라이드(7/2=3, 5/2=2)로 풀링 영역(➌)을 정하고 최대 풀링을 적용
⇒ 2×2 결과(➍)를 얻을 수 있음


6.2.4 Faster R-CNN
Faster R-CNN이란?
- '더욱 빠른' 객체 인식을 수행하기 위한 네트워크
- 후보 영역 생성(기존 Fast R-CNN 속도의 걸림돌)을 CNN 내부 네트워크에서 진행할 수 있도록 설계
: Faster R-CNN에서는 외부의 느린 선택적 탐색(CPU로 계산) 대신 내부의 빠른 RPN(GPU로 계산)을 사용
∴ 기존 Fast R-CNN에 후보 영역 추출 네트워크(Region Proposal Network, RPN)를 추가한 것
Faster R-CNN 구조

RPN(후보 영역 추출 네트워크) : 마지막 합성곱층 다음에 위치
그 뒤는 Fast R-CNN과 동일하게
• Rol 풀링
• 분류기
• 바운딩 박스 회귀가 위치
후보 영역 추출 네트워크

① 특성맵 N×N 크기의 작은 윈도우 영역을 입력으로 받음
② 이진 분류를 수행하는 작은 네트워크 생성 : 해당 영역의 객체 존재 유무 판단용
③ 바운딩 박스 회귀를 추가 : 위치 보정(좌표점 추론)용
④ 슬라이딩 윈도우 방식으로 앞서 설계한 윈도우 영역(N×N 크기)를 이용하여 객체를 탐색 : 하나의 특성맵에서 모든 영역에 대한 객체의 존재 유무 확인용
후보 영역 추출 네트워크의 단점
이미지에 존재하는 객체들의 크기와 비율이 다양함
→ 고정된 N×N 크기의 입력만으로는 다양한 크기, 비율의 이미지를 수용하기 어려움
→ 보완 방법 - 앵커(anchor)
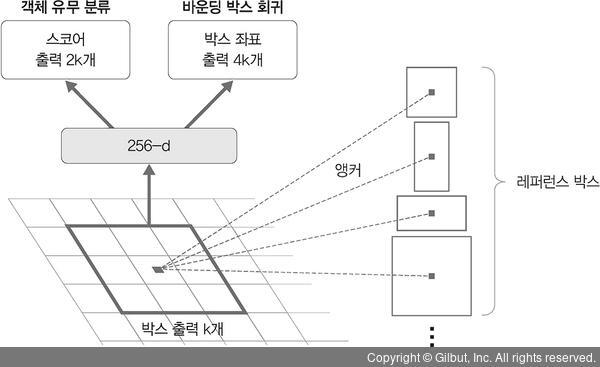
📝Note. 앵커란?
: 여러 크기와 비율의 레퍼런스 박스 k개를 미리 정의
& 각각의 슬라이딩 윈도우 위치마다 박스 k개를 출력하도록 설계하는 것
⇒ RPN의 출력 값
① 모든 앵커 위치에 대해 각각 객체와 배경을 판단하는 2k개의 분류에 대한 출력(객체용 박스 k개 + 배경용 박스 k개)
② x, y, w, h 위치 보정 값을 위한 4k개의 회귀 출력
예) 특성맵 크기가 w×h라면, 하나의 특성맵에 앵커가 총 w×h×k개 존재
'Etc > Deep Learning' 카테고리의 다른 글
| 7장 시계열 분석(1) - 시계열 데이터 분류, 시계열 분석 모델, 순환 신경망(RNN), RNN계층과 셀 (0) | 2021.08.21 |
|---|---|
| 6장 합성곱 신경망Ⅱ(5) - 이미지 분할을 위한 신경망(U-Net부터 내용추가하기) (0) | 2021.08.17 |
| 6장 합성곱 신경망Ⅱ(3) - 이미지 분류를 위한 신경망(VGGNet, GoogLeNet, ResNet) (0) | 2021.08.11 |
| 6장 합성곱 신경망Ⅱ(2) - 이미지 분류를 위한 신경망(AlexNet) (0) | 2021.08.10 |
| 6장 합성곱 신경망Ⅱ(1) - 이미지 분류를 위한 신경망(LeNet-5) + 실습 : 🔜파이썬 개념 추가 정리하기 (0) | 2021.08.09 |